
What Happened?
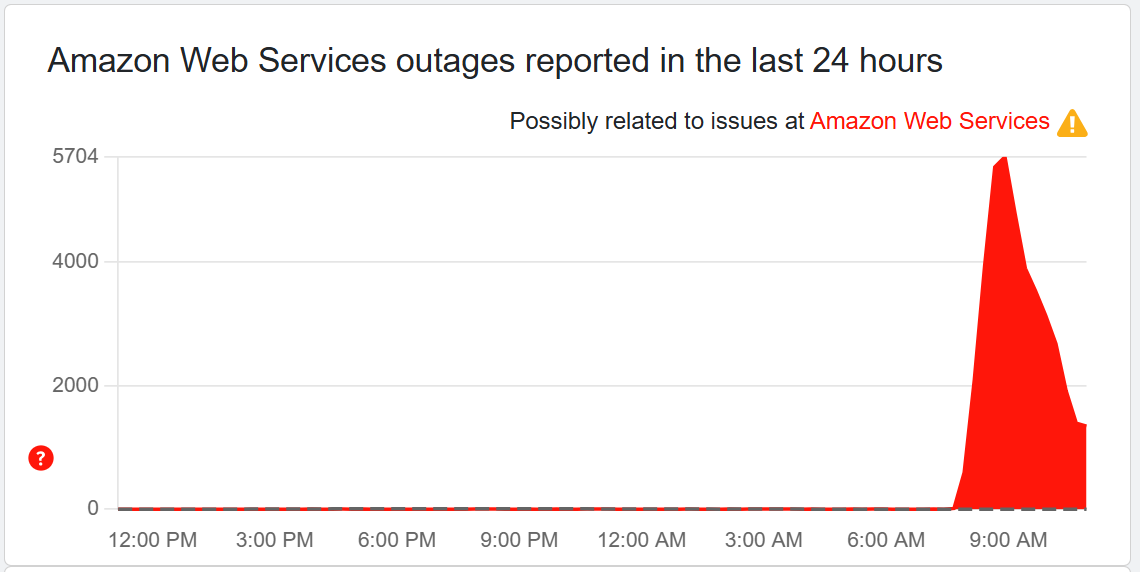
On October 20, 2025, Amazon Web Services (AWS) experienced a significant outage originating from its US-EAST-1 region in Northern Virginia. The disruption began around 3:11 AM ET and was traced to DNS resolution failures affecting the DynamoDB API endpoint. This led to widespread service failures across major platforms, including:
-
Snapchat, Ring, Alexa, Fortnite, Roblox, Duolingo, and Canva
-
Major banks such as Lloyds, Halifax, and Bank of Scotland
-
Government services like HMRC and National Rail
-
Retailers and fintech platforms including Coinbase and McDonald's
By 6:35 AM ET, AWS reported that the underlying DNS issue had been fully mitigated, and most services were returning to normal. While the primary issue has been addressed, some services may still be experiencing residual effects, such as throttling or delayed request processing, as they work through backlogs (Newsweek). However, the overall situation is improving, and most major services have resumed normal operations.
Why It Matters
This outage underscores the fragility of our digital infrastructure. Over reliance on a single provider or region can lead to widespread disruptions. As cybersecurity expert Marek Szustak noted, "When domain name resolution stops working, entire applications and services can stop responding" (The Guardian).
What to Do Next: Building Resilient Digital Experiences
For businesses and developers, this incident highlights the importance of proactive measures to ensure service continuity:
-
Implement Multi-Region Architectures
Distribute workloads across multiple AWS regions or even different cloud providers to mitigate the impact of regional outages. -
Automate Backups and Failover Mechanisms
Regularly back up data and configure automatic failover systems to maintain service availability during disruptions. -
Conduct Regular Disaster Recovery Drills
Test your systems' response to outages to identify weaknesses and improve recovery times. -
Monitor and Alert
Use monitoring tools to detect issues early and set up alerts to inform your team of potential problems.
Leverage Intergence's Expertise
At Intergence, we have extensive experience in all aspects of IT resilience - from designing multi-region architectures and automating backups to conducting disaster recovery drills and proactive monitoring. As a trusted Microsoft partner, we specialise in Azure solutions but also bring experience from AWS projects. Our team can tailor these strategies to your organisation, ensuring your services remain resilient and highly available, no matter what challenges arise.
Get in touch with us at www.intergence.com or call us on 01223 800530.